The case against event sourcing
Traditionally most applications model the main components of a system as entities and implement mechanisms to create/update these entities in the form of state that is stored in a database. This modeling although is natural (and relatively straightforward to implement) has certain limitations that not every domain is able to accept. For example, if you are modelling a banking system is not enough to store information only about the customer’s current balance, you need to have information about all the actions that resulted to that balance e.g. for fraud detection reasons, for auditing or even for better user experience. As a result of these requirements is not enough to just store the latest state of an entity.
Event sourcing is the practice of storing a series of events over time and recreating the latest state of an entity by replaying these events. For example:
- The user places an order
- The user updates the order by applying a voucher she received because she subscribed to our newseletter.
- The user cancelled the order providing a reason
In a traditional modelling approach this would be translated in something like the following in the database:
| order_id | is_cancelled | created_at | updated_at |
|---|---|---|---|
| 12 | true | 2021-02-05 | 2021-02-07 |
in a system that uses event sourcing it will be something like this:
| id | order_id | type | data (JSON) | created_at |
|---|---|---|---|---|
| 23741321 | 123 | created | { products: […] } | 2021-02-05 |
| 53212319 | 123 | voucher_applied | { discountpercent: 30 } | 2021-02-05 |
| 83412325 | 123 | order_cancelled | { cancellation_reason: ‘too expensive’ } | 2021-02-07 |
To be able to see the current state of an instance of an entity the system has to replay all the events that
are related to it and transform the instance to reflect the latest state. For example, our application could
request from the database all the events related to order with order_id 123 and based on the type call different
functions to create an instance of the Order entity and transform it to reflect the desired state. Obviously, this
would be extremely inefficient, imagine having the entity BankAccount and to retrieve the latest state of it
you have to replay all the transactions the customer ever made. One solution to this problem that is usually used in
conjunction with Event Sourcing is the the CQRS pattern.
In CQRS one component/subsystem of the system is responsible for handling writes to the database and another for handling reads, the writes are replicated from the “writes store” asynchronously to the “read only data store”, this of-course sacrifices data consistency for having (theoretically) higher performance and independent scaling (read store can scale independently from the write store and also use different technologies). The system relies on eventual consistency (if you wait long enough and there are no new writes you can get the latest valid state) A typical (simplified naive) implementation of this pattern would look like this:
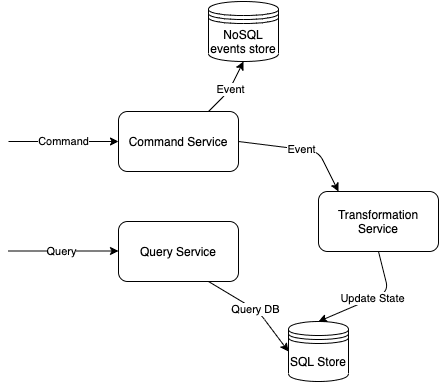
- The command service is handling all the write request and persist them in a data store. Typically this is a schema-less NoSQL database because of the diversity in the shape of event payload. The command service emits an event (usually without any modification to it).
- A separate service (I called it transformation service) is responsible for listening these events and update the read only data store. This typically is a SQL datastore.
- A query service is handling all the reads. It receives read requests and fetches the related data from the SQL database.
This design brings certain benefits:
- As mentioned the subsystems that handle read and writes can scale independently, offering higher availability and performance.
- We store all the changes ever made to the system, that makes it very easy for someone to inspect how the system derived its current state (e.g. authorities to inspect the transactions in a banking account).
- We can replay as many events as we want to see the state of an entity at certain point in time in the past, something very useful for debugging.
- We can analyse events to see patterns in the system (e.g. high number of
order_cancelledevents straight aftervoucher_appliedevents could mean that something is wrong with our vouchers)
As is the case with any design there are also a number of challenges on this one too, but I want to focus on a particular problem, schema evolution. Imagine that we have a system that runs for a few years and receives among other Customer Complains as events.
The event is looking like this:
{
customer: { name: 'Avraam Mavridis' },
complain: { content: 'My order was delayed' }
}A new business requirement comes, data analysts want to be able to easily filter the complains based on some predefined types, so our event has to evolve and take a new shape, something like these:
{
customer: { name: 'Avraam Mavridis' },
complain: {
content: 'My order was delayed',
reason_type: 'delayed_order'
}
}Another requirement comes that requires us to split the name field into first_name and last_name. Our event has to
change shape again and become something like:
{
customer: { first_name: 'Avraam', last_name: 'Mavridis' },
complain: {
content: 'My order was delayed',
reason_type: 'delayed_order'
}
}In the first case we had the introduction of a new field (reason_type), in the second type we have to break an existing field (name) into 2 new fields (first_name and last_name). Now the question is:
How are we gonna deal with these changes in the Transformation Service?
First I have to say that I find the term schema-less quite misleading. Its not that there is no schema, there is, the schema is not in the database layer, it is implicitly (or semi-explicitly) defined in the application itself which has to deal with any schema change (in our case Transformation Service).
Now how can we deal with the changes in the schema:
Data migration
The idea is simple, we write scripts to transform the existing records to fit to the new schema. Depending on the situation this can be easy, or very challenging (imagine having to do special parsing to split a field into 2 fields). Another challenge is the amount of data, potentially you may have to transform a huge number of records. As a side effect you also lose the history, this may or may not be important, but ultimately you change the shape of how each entity was looking in the past.
Multiple schema versions
One idea is to use schema versioning and refactor the Transformation Service to be able to deal with all the possible schema versions. In that case our Transformation Service should be refactored to be able to handle all the possible schema versions. Obviously it will become too messy if for every little change in the schema we have to adjust our application to handle the new schema version.

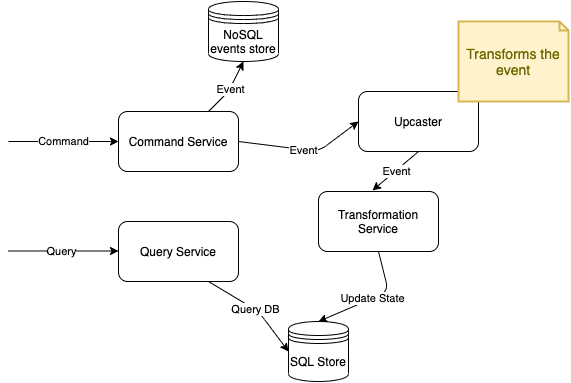
Upcasting
The idea here is that we have a single component that transforms the event before passing it to the listener, the difference is that our application do not have to handle schema changes.
Summary
I found all the available solutions not very fulfilling, and although event sourcing is a nice technique which can be used in a variety of problems, I would be very reluctant to use it without having a good understanding on how often the schema of the events change, who is responsible for the changes, if keeping the historical shape of the events in the store untouched is important and the amount of data my system would potentially have to deal with.