Knowledge coupling
When we hear “coupling” in the software industry, we often think of it as something negative. However, some level of coupling is necessary for things to function after all. The issue lies in the extent of this coupling. Coupling can occur in different ways, both in “space” and “time”. In this blogpost I will focus on one type: coupling in knowledge sharing. By “knowledge sharing”, I mean how much implementation detail the components of a system need to know about each other. I used some examples in Rust below but the coupling doesn’t have to be between classes (structs) or interfaces, you can also consider it as coupling between modules of a monolith or between microservices of a distributed system, the concept is the same. The more knowledge shared across coupled components’ boundaries, the more they are susceptible to cascading changes.
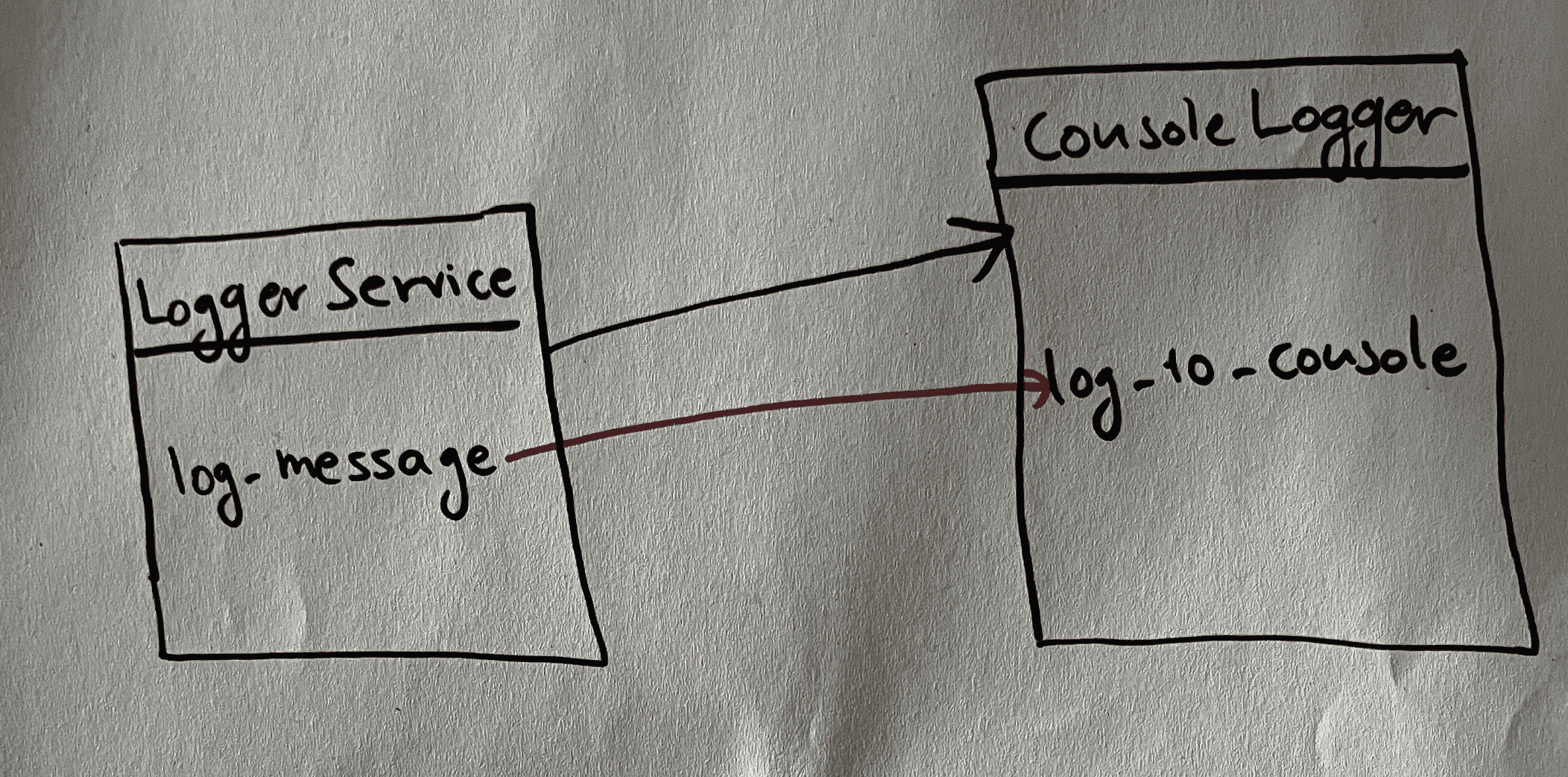
Consider a LoggerService module. It provides basic functionality to log messages and works with a logger object that encapsulates the logging mechanism. Bellow we will explore three different degrees of coupling:
Concrete Implementation Dependency
struct LoggerService {
logger: ConsoleLogger,
}
impl LoggerService {
fn new(logger: ConsoleLogger) -> Self {
LoggerService { logger }
}
fn log_message(&self, message: &str) {
self.logger.log_to_console(message);
}
}
struct ConsoleLogger;
impl ConsoleLogger {
fn log_to_console(&self, message: &str) {
println!("{}", message);
}
}In this design, the LoggerService depends on a concrete ConsoleLogger implementation, the expected passed logger to create a new LoggerService is of ConsoleLogger type and thus the two componnets are highly coupled. Changing the logging mechanism, such as using a file logger, will require changes in the LoggerService.
Interface Dependency with specific methods
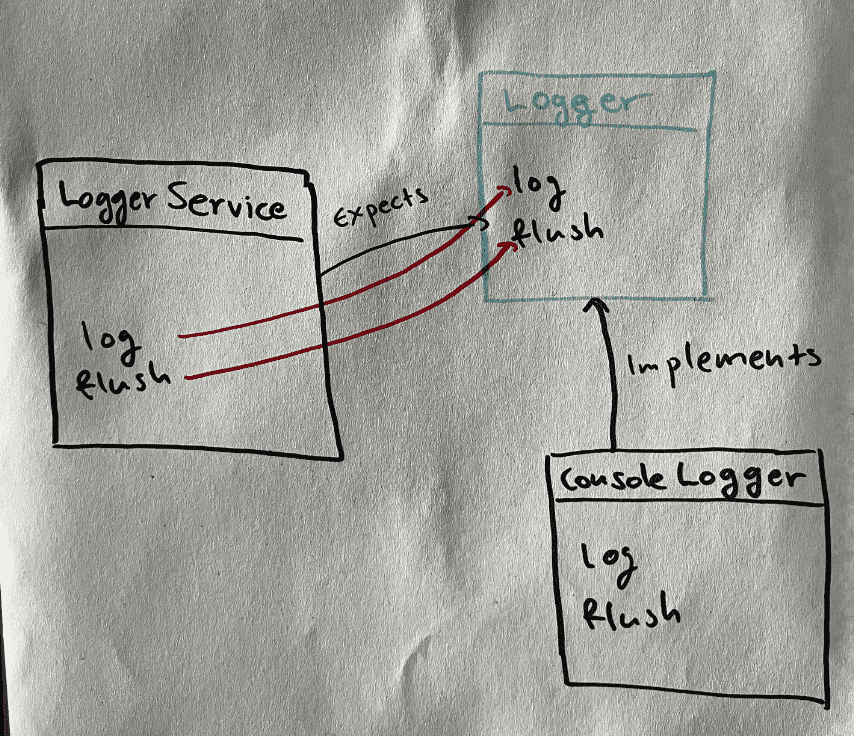
struct LoggerService<L: Logger> {
logger: L,
}
impl<L: Logger> LoggerService<L> {
fn new(logger: L) -> Self {
LoggerService { logger }
}
fn log_message(&self, message: &str) {
self.logger.log(message);
self.logger.flush();
}
}
trait Logger {
fn log(&self, message: &str);
fn flush(&self);
}
struct ConsoleLogger;
impl Logger for ConsoleLogger {
fn log(&self, message: &str) {
println!("{}", message);
}
fn flush(&self) {
}
}Here, the LoggerService depends on a Logger trait (aka interface). While the LoggerServive do not expect specifically a ConsoleLogger but any object that implements the Logger interface, it depends still on specific methods of it (log, flush). In case we want to switch to a different Logger that do not use/need these methods things start to not fit well.
Interface Dependency with abstract methods
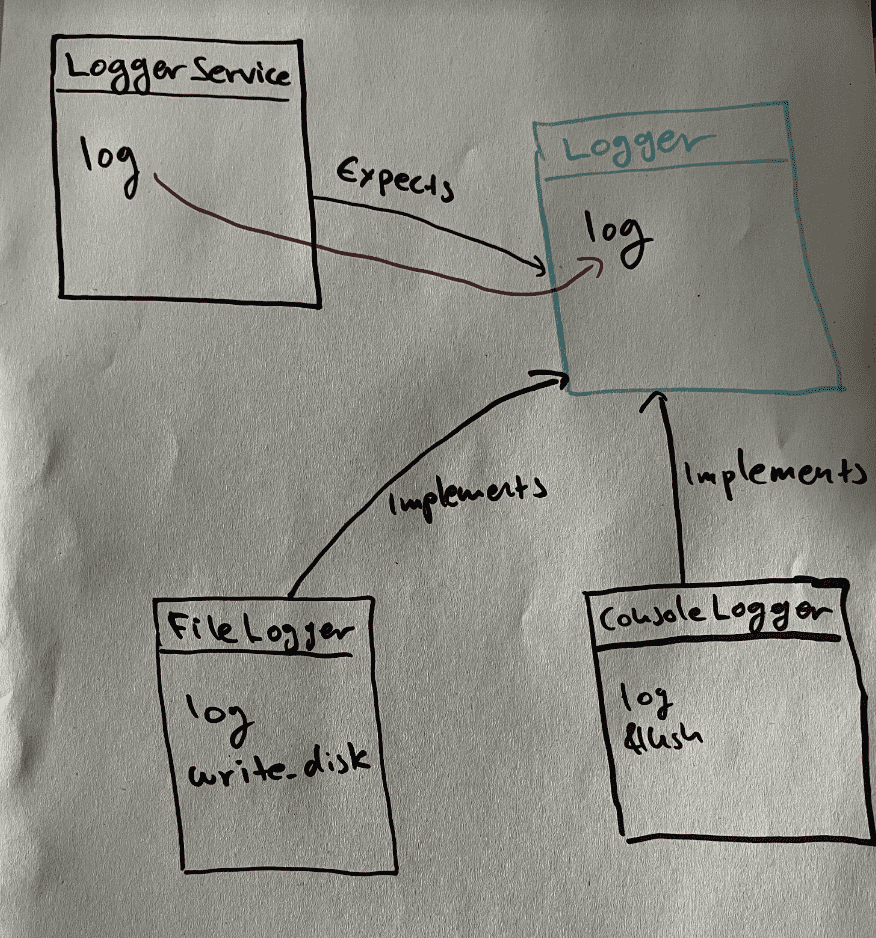
struct LoggerService<L: Logger> {
logger: L,
}
impl<L: Logger> LoggerService<L> {
fn new(logger: L) -> Self {
LoggerService { logger }
}
fn log_message(&self, message: &str) {
self.logger.log(message);
}
}
trait Logger {
fn log(&self, message: &str);
}
struct ConsoleLogger;
impl ConsoleLogger {
fn flush(&self) {
}
}
impl Logger for ConsoleLogger {
fn log(&self, message: &str) {
println!("{}", message);
self.flush();
}
}In this design, the Logger trait exposes a single abstract method log, abstracting away the underlying logging mechanism details. This allows the LoggerService to work with a variety of logging implementations without needing to update its abstraction. The concreate loggers have to encapsulate any detail and only expose a log method.
Summary
- Concrete implementation dependency shares the most knowledge: the specific class/module/component being used.
- Abstract interface dependency with specific methods reduces knowledge to the interface, but specific methods still used.
- Interface dependency with abstract methods encapsulates further and exposes only the minimal, more abstract methods needed.
The more knowledge is shared, the more shared reasons for change the coupled components have and any changes to the “knowledge” have to be propagated across the affected components/classes of the system.