SDLC Development Principles
Defining clear operating principles is essential for any software engineering team to function effectively. These guidelines, while not easily automated, ensure the health and stability of both the systems and the team. Here I describe some of the ways I use in my day-to-day work.
Start by defining the operating principles
It is important that the team agrees and defines some operating principles. These are processes that are not easy to automate but are crucial for both the health of the systems and the health team. Some examples may include:
- How do we conduct pull request reviews? It is important to agree on the process. Different teams and systems have different needs. You may have services that are very critical and require two approvals before merging to the main branch, while others are less critical (e.g., a bot developed for sending notifications on Slack may not be as critical as your Payments Service).
- How do we merge to the main branch? Do we squash our commits or not? How should the commit message look? What tasks should be fulfilled before merging?
- What is the responsibility of the on-call person?
- What is the process for deploying services? You may decide that special agreement from the team leadership is required to deploy something after 17:00, or that the engineer who does the deployment has to stay at least 3 hours after the deployment to monitor it. These are things that are hard to automate with a tool but are very critical.
Re-review these decisions periodically. In my teams we have a Ways of working meeting every 2 weeks where we only talk about the how we execute our work. It is not a retro, it doesn’t focus on the previous two weeks, it a meeting that we touch topics similar to the ones mentioned previously.
Document these decisions. People come and go and the shape of the team is evolving constantly, for new joiners it is important to know the context of why a certain way of working has been established. In my teams we document these decisions in the internal Wiki, the document usually has similar structure with an ADRs but it is solely focusing on decisions about the ways we work.
Define technical guidelines
Similarly, agree on certain technical guidelines for developing software. These can be a tech radar defining the languages/frameworks we are allowed to use, a REST API Guidelines document for your APIs, linting rules (e.g. using camelCase vs snake_case), agreed patterns (e.g. use dependecy injection etc), a service rulebook where it defines the nessecary requirements for developing a new service (e.g. tagging resources with service name, using correlation-ids etc)
Automate, automate, automate
Automate as many things as possible, to increase efficiency and avoid conflicts for things that essentially do not add value to the end customer. These can be things like:
- Linters and formatters
- Pre-commit hooks that do certain checks
- Automatically pulling the right reviewers based on what file changed in a mono-repo etc
- Configuring Dependabot or similar tool to help with depedency updates
- Linking issue tracking system tickets with pull requests
- Notifying slack for failing builds
- Code coverage reports
- Use SonarQube to find code smells etc
There are tons of things that you can automate to increase efficiency and ensure certail level of quality.
Link product requirements with the technical solution
Many times engineers tend to jump into the implementation before discussing the potential solution, its crucial to establish a process that a technical solution is discussed before we jump straigh to implementation. This can involve an RFC document where various approaches are discussed to solve the issue (or develop the feature), or even an SDD/SDR (System Design Document / System Design Review) if its a new service or system we aim to develop.

RFC Document

System Design Document
Testing
I have seen many times the testing coming as an after thought, or the engineers focusing on writing unit tests because writing end-to-end tests are too complicated or too time-consuming or the tests are too fragile or flacky. It is very crucial to be part of the process.
Define what should be tested and in what extend, make the tests a requirement for the review process, incorporate them in your CI/CD pipeline. This is the alphabet.
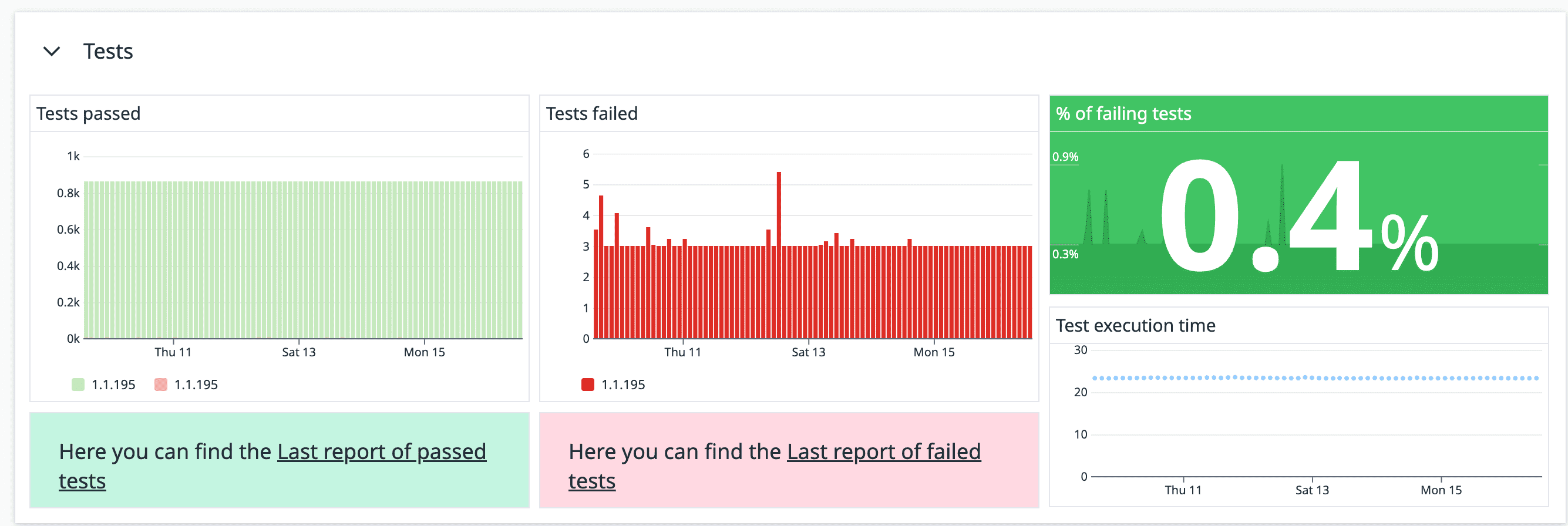
Go a step further: test as if you are the customer and test continuously. In today’s world, a system is developed by various teams, and many times you rely on external parties. Maybe AWS is down, maybe a service provided by another team is down, maybe someone added a change in your mono-repo that affects your frontend, maybe someone changed the copy in the CMS to something that doesn’t make sense, etc. Test the critical flows end-to-end, not only when something merges but constantly, and add alerts based on your tests to catch issues even before your customer reports them. That’s what we did in one of my teams: we have a container running that executes a test suite every 10 minutes and reports metrics to Datadog. Based on these metrics, we have alerts that notify on Slack and/or OpsGenie to catch issues before they are discovered by customers.
Identifying test case before writing the software, I am not talking about TDD here. I am talking of uncovering edge cases by reviewing what we aim to build. In my teams this is part of the RFC process and a section in the relevant document, there we highlight the things that we need to test, by discussing them as a team we uncover edge cases that the engineer who wrote the RFC may haven’t thought.
Test on staging but also test on production. In a perfect world, you have an environment (or two) where you can test things, and ideally, this environment behaves the same as production. However, we don’t live in a perfect world, and for various reasons, there may be a drift between your staging and production environments, or you can’t make them the same (e.g. you can’t have real personal data in staging). In my teams, for critical releases, we also schedule a “bug bash” session where the whole team tries to execute various flows and observe the system’s behavior. This is a rare event suitable only for significant changes, do not do it because you turned a button from blue to pink.
Monitors, Alerts, Logs and Traces
Establish and monitor performance statistics with respect to response time, error rate, system uptime, and usage of resources. Ensure these statistics are maintained at agreed-upon performance levels based on your team’s objectives and SLAs. The main two methodologies are USE and RED, RED (Rate,Errors,Duration) is more suitable for request-driven systems (e.g. services exposing API endpoints) while USE (Utilization,Saturation,Errors) is focusing more on system resources, you dont have to choose one, many times you have to implement both. Monitor both application and infrastracture metrics.
Establish dashboards to ensure real-time visibility, Datadog and Grafana are great tools. Usually which tool you use is not make a huge difference and is mostly a matter of cost and effort. Set up alerting for critical metrics and thresholds. Ensure timely notification with PagerDuty and OpsGenie tools for effective incident management.
Logs can help you debug issues, in my experience is useful to define a schema for the logs that all your services respect and certain metadata that helps you query the logs. Everyone in the team should become familiar with the tool you picked (no matter if is Splunk or ChaosSearch) to be able to debug issue effectively.
Technical debt management
It is important to have a shared understanding of what technical debt is because there are often two misconceptions around the concept: what it is and who is affected.
Misconception 1: What is technical debt? Technical debt is bad code that annoys engineers, legacy code developed by an external agency eight years ago, code developed by juniors, or code written in a non-trendy language like PHP. Spoiler alert, none of the previous are nessecarly tech debt.
Misconception 2: Technical debt only affects engineers (and their mood). Spoiler alert, affects everyone.
For me, technical debt in practice is a decision we make to cut corners to deliver something quickly now, fully aware and accepting that it will slow us down later. It is an obligation for future technical work we may have to undertake.
At the end of the day everyone agrees that tech debt is not good and we should try to reduce it, the problem is that there is not an agreement on how and by how much. I have seen the following patterns:
- Allocate X% of the Sprint time for tech debt
- Spawn a tech debt team that will only address that and when done the engineers will again be distributed to product teams
- “Leave the place better than you found it”
None of this really works in my experience. First of all, it’s harder to estimate the effort required to address tech debt than it is to estimate the delivery of a feature, and we are already not very good at that as an industry. Allocating 20% of the sprint to address technical debt usually leads to people picking small tasks that improve the codebase slightly but do not address deeper or bigger issues. I have also seen the creation of a tech debt team to address a specific problem for 2-3 weeks, only to disband the team afterward. In my opinion, this removes the obligation from the people who introduced the tech debt in the first place and creates a bad culture. We should increase ownership and accountability, and this doesn’t help.
Another pattern I have seen is the “leave the place better than you found it” approach. While that is great advice, it is often impractical. If you develop a feature that you estimated would take one week but end up spending 1.5 months to rewrite everything to leave the place better, it may not matter because business requirements might have changed.
The only thing I have seen working is creating empathy between product, business, and engineers, establishing a common understanding of what technical debt is and who is affected, and incorporating it into the roadmap. Not just into sprint planning—INTO THE ROADMAP. It has to be part of the roadmap and its strategy. You may have areas of technical debt that no one uses or cares about; you know they are bad, and you wish you had time to improve them, but they do not slow you down in the future. That is an acceptable technical debt you can live with.
Learn from mistakes
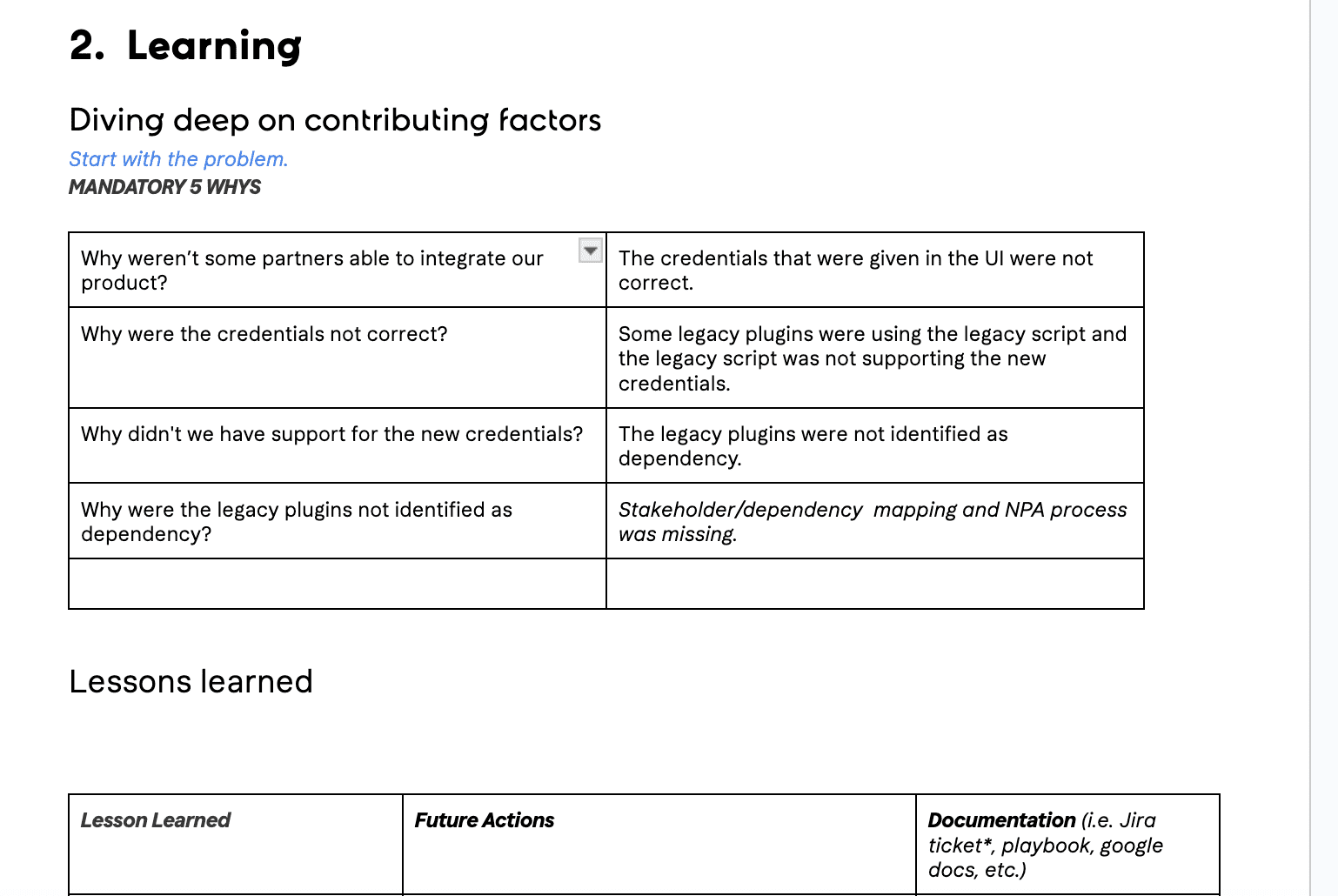
“Success does not consist in never making mistakes but in never making the same one a second time.” is the saying, everyone makes it is important to learn from them, it is also important to not only learn from our own mistakes but from the mistakes others make. This can be done in various forms, either in retros, in discussions about bugs or more formally in post-mortems. It is important to have documented in a structured way the incident you experience and what you learn from them.
I am a big fan of Nassim Taleb and have read all his books 2-3 times. My all-time favorite, which can be an inspiration for the profession, is “Antifragile” (you can watch the talk here). “Antifragile” describes systems that not only withstand shocks, volatility, and stressors (incidents and bugs in our world) but actually benefit and grow stronger from them. I love this concept because I also believe that if we learn from our mistakes, our systems will become not just robust but antifragile.