Schema on Write vs Schema on Read vs Adjusting to a Schema using an LLM
I was exploring an idea the other day, fixing the data on a database using an LLM, and this is an article that discuss this approach. There are basically two fundamental ways on how data is ingested, stored and processed: schema on write and schema on read.
Schema on Write
Schema on write is the traditional approach where the schema of the data has to be defined beforehand and no deviation from it should be allowed. Strong typing of the data is enforced for consistency and integrity in the data, which makes it a good fit for relational databases and is suited for analytics purposes.
However, schema on write is restrictive in its own way. It requires rigorous planning and design prior to data ingestion, otherwise flexibility becomes weak when one tries to cope with changes. Changing the schema after the data has been stored is a hard and expensive process. Have you ever tried to run scripts to fix millions of records in a DB? Then you know what I mean.
Schema on Read
On the other hand, schema on read defers the schema definition until data is read or queried. It stores data in its raw format and applies schema when data is retrieved. Ingestion happens quite fast, as there is no upfront schema enforcement, you just write whatever you get. It suitable in an environment whereby data is continuously being generated from many sources at high speed, and the structure might change with time.
| Feature | Schema on Read | Schema on Write |
|---|---|---|
| Flexibility | High flexibility; schema can change easily. | Less flexible; changes to schema require data reload. |
| Data Storage | Data stored in raw format, often unstructured. | Data stored in structured format according to schema. |
| Performance | Slower reads due to on-the-fly schema application. | Faster reads as data conforms to predefined schema. |
| Use Case | Suitable for exploratory data analysis, big data applications. | Common in traditional databases, ensures data consistency. |
| Error Handling | Errors detected during data reading. | Errors detected at data entry point. |
| Examples | Hadoop, NoSQL databases like MongoDB. | Relational databases like MySQL, PostgreSQL. |
The issue with Schema on Read
In the schema on read approach, typically there’s a need to identify a mapping of how raw fields of data correlate to the expected schema at process or query time. Applications accessing the data should know how to interpret the various fields. This may include specifications for even how fields of raw data map into columns or elements of the desired schema. This can require that the mapping logic is constantly maintained and adjusted, something that can be costly or even not possible.
Scenario
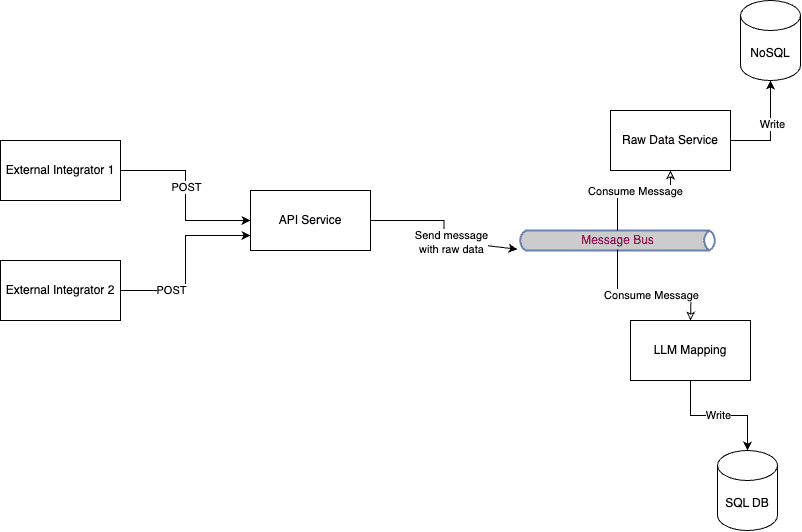
Imagine you are building an API that others will use to POST customer information. You have two options:
- Define an API with a rigid schema that integrators must follow.
- Allow integrators to POST in whatever format they prefer.
In many cases, the second option might be the only feasible one, as it can be challenging to persuade external parties to conform to your schema. In such cases, a Schema on Read approach must be adopted, and you will need to maintain a mapping between your schema and what these external parties provide. This can be very difficult since you do not control the external party, and they may make changes without notifying you.
Using an LLM to adjust to a Schema
What if we you have the best of both worlds?
- Allow integrators to give us whatever data they have in whatever shape they have it.
- Adjust the raw data to a schema for easier analysis.
- Do not have to maintain manually a mapping.
And on top of the previous, what if we can “fix” also some data on the way. The idea here is to use an LLM to help us do the mapping and fix when possible the data.
For example giving the following instructions to an LLM:
You are acting as a processor of incoming requests and you have to match the payload with the following Schema:
{
"firstName": "string", // First name of the user
"lastName": "string", // Last name of the user
"email": "string", // Email address of the user
"phoneNumber": "string", // Phone number of the user
"address": {
"streetAddress": "string", // Street address
"city": "string", // City name
"state": "string", // State or region
"postalCode": "string", // ZIP or postal code
"country": "string"
},
"dateOfBirth": "string",
"gender": "string", // Gender of the user
}
You have to also correct the datapoints when relevant using the following rules:
country should be the country code, not the country name.
dateOfBirth should be in YYYY-MM-DD
I will give you a payload and you have to adjust it to the schema.And posting the following data for correction:
{
"first_name": "Avraam"
"last_name": "Mavridis"
"email": "avr.mav@gmail.com",
"phone_number": "1234567",
"address": {
"address": "Quart",
"city": "Berlin",
"state": "Berlin",
"postal_code": "12034",
"country": "Germany"
},
"date_of_birth": "24-08-1987",
"gender": "male",
}The LLM does the mapping and gives us back:
{
"firstName": "Avraam",
"lastName": "Mavridis",
"email": "avr.mav@gmail.com",
"phoneNumber": "1234567",
"address": {
"streetAddress": "Quart",
"city": "Berlin",
"state": "Berlin",
"postalCode": "12034",
"country": "DE"
},
"dateOfBirth": "1987-08-24",
"gender": "male"
}Key adjustments:
- Changed country from “Germany” to its country code “DE”.
- Formatted dateOfBirth to “YYYY-MM-DD”.
- Updated keys to match the schema format (camelCase instead of snake_case)
Considerations
The use of an LLM in dynamic schema mapping for data ingestion enables more flexibility and removes the need for manual updating mappings but it has a few challenges:
- Accuracy and reliability: LLMs can sometimes misinterpret or inaccurately convert data. If data processing needs to be entirely accurate, then this method should be treated with caution.
- Performance: Processing huge data volumes through an LLM can be resource-intensive and slow, and this might affect real-time applications. This approach is usually better as a post-process step.
- Security and privacy: Handling sensitive data requires strict security measures to maintain data integrity and comply with regulations. For enhanced security & privacy, running the LLM locally, rather than using external services like the OpenAI API might be preferable.
- Cost: In some cases, the use of LLM in data processing may be quite expensive, which might not justify the costs for every scenario.
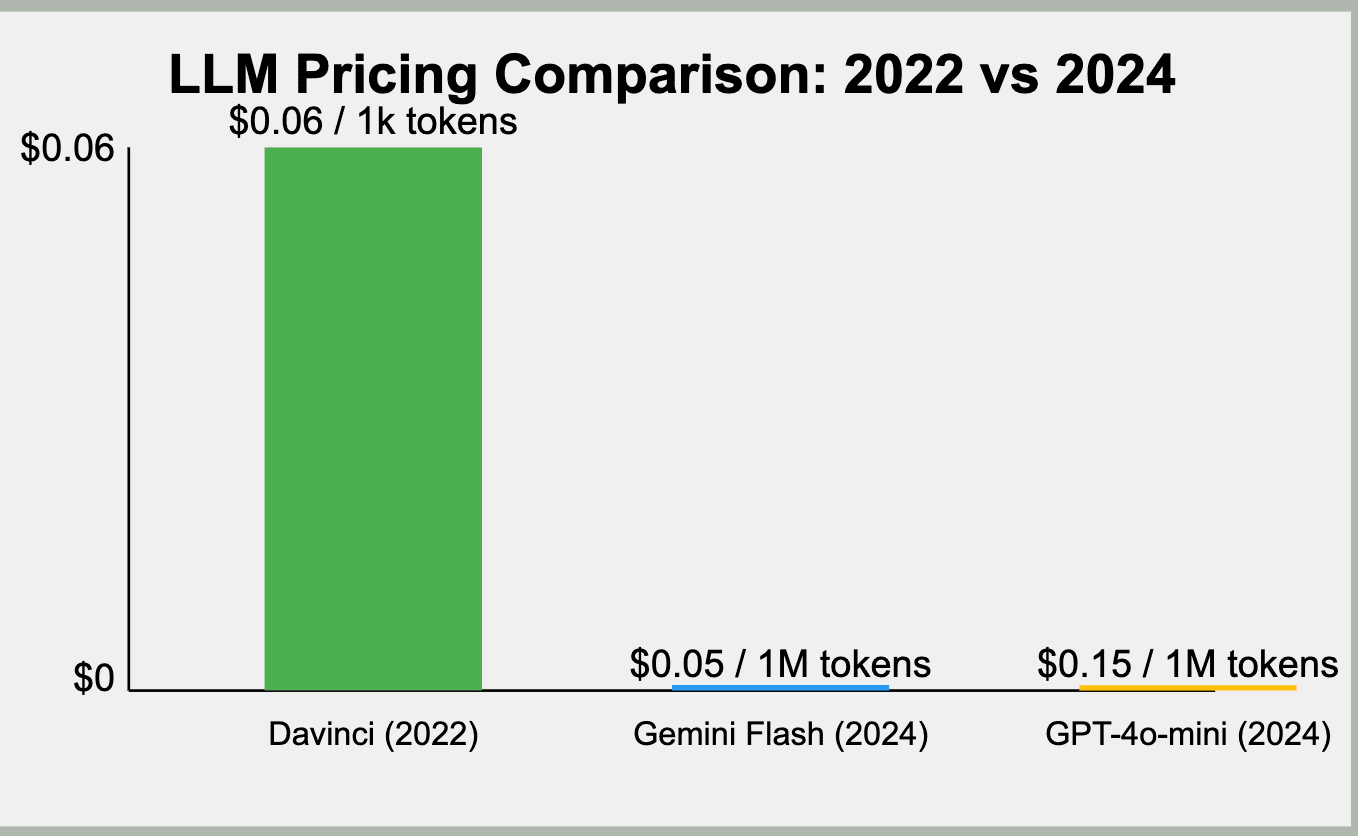
I expect the accuracy and performance to get better over time while the cost is getting reduced. In less than 2 years we got 100x cheaper models (that are much smarter).