Faster sampling in PostgreSQL
Many times we want to display some random data to the user, for example if you have an e-commerce website apart from the top products or some list of products that a fancy recommendation system generates, you want to display to the user a list of random products.
Picking random records from a set of records is similar to what statisticians call sampling:
In statistics, quality assurance, and survey methodology, sampling is the selection of a subset (a statistical sample) of individuals from within a statistical population to estimate characteristics of the whole population. Statisticians attempt for the samples to represent the population in question. Two advantages of sampling are lower cost and faster data collection than measuring the entire population. - Wikipedia
Another case could be when you want to extract information about a population where choosing a subset of it could be sufficient for your analysis, for example if you had a table of 10000 employees and you wanted to find the average salary, it would be (assuming your sample do not have only extreme values) enough to calculate the average of 1000 employees.
Obviously one way to do that is to fetch the whole table, and pick some random rows in the application level, but that is time/memory consuming. If we want to improve the performance we have to do this kind of calculation in the database level.
Let’s say that we want to retrieve a sample of 10 random records from a table, one way to achieve
that would be to Select with a random OFFSET.
SELECT * FROM products OFFSET (
RANDOM() * (
(Select count(*) FROM products) + 1)
)
LIMIT 10;My table had 12000 records, after some tests I got:
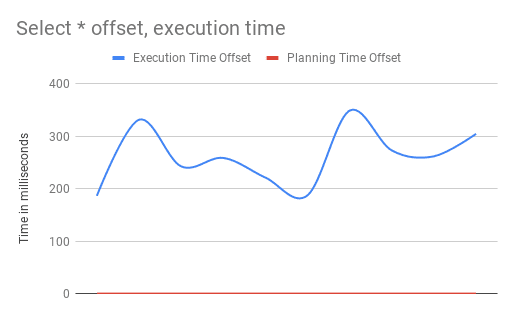
One thing to notice on the chart is that the performance of the query is not consistent,
another thing is that the records are not as random as you would probably like them to be,
OFFSET essentially discards some records from the beginning of the table and takes the
m next rows, in our case because of the LIMIT the next 10 rows.
The average execution time in my case for the OFFSET technique was 261.367ms
To “fix” the randomness we can select and order randomly
SELECT * FROM products ORDER BY RANDOM() LIMIT 10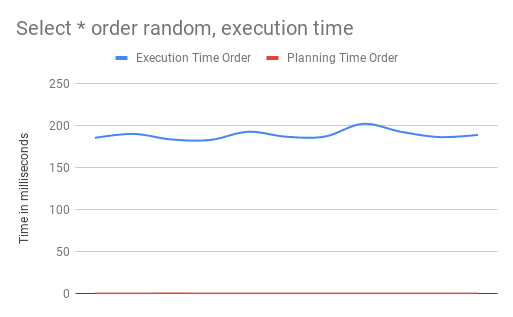
The average execution time in my case for the ORDER technique was 188.8964ms,
its an improvement compared to the offset technique but let’s be honest, it is still
slow. The reason behind the poor performance is that they operate on the whole table.
PostgreSQL (since version 9.5) has built-in support for sampling.
We can take a sample of the table and run our queries on that instead of the whole table.
Sampling can be done using the TABLESAMPLE function and it supports 2 different ways to
do sampling BERNOULLI and SYSTEM.
BERNOULLI is sequential, meaning that it generates the sample by picking random records
from the whole table, while SYSTEM works on the page level, it constructs the sample by picking
blocks of records.
My table is splitted into 342 pages, and BERNOULLI could potentially visit all of them
SELECT pg_relation_filepath(oid), relpages
FROM pg_class WHERE relname = 'products';
To generate random data using BERNOULLI we can do
SELECT * FROM products
TABLESAMPLE BERNOULLI(1) LIMIT 10;We specify the percentage of the table we want to use as sample, in my case I
requested 1%
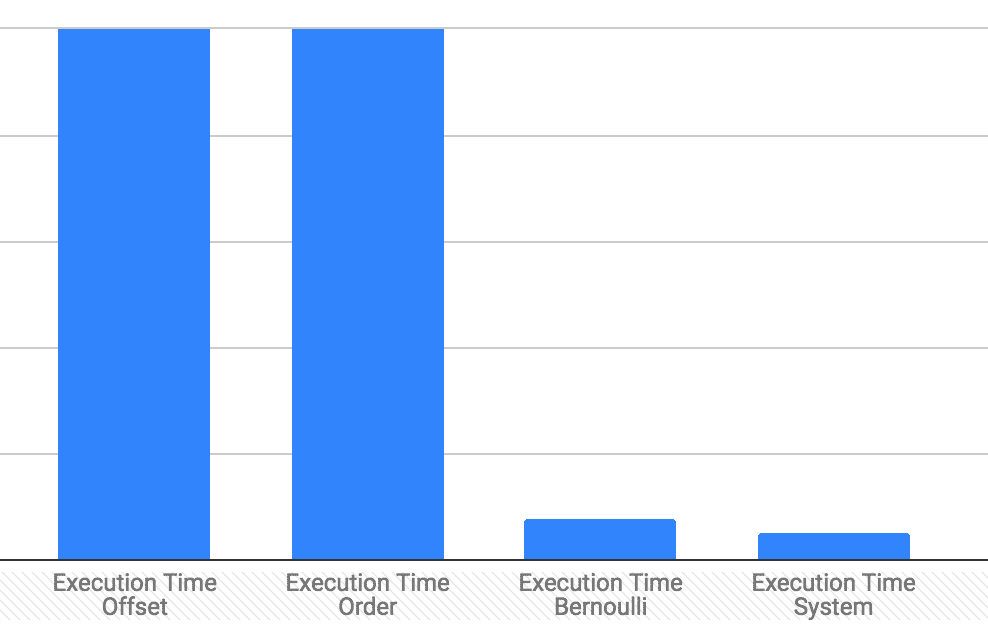
Doing some tests to calculate the execution time we see that using sampling improves the performance tremendously.
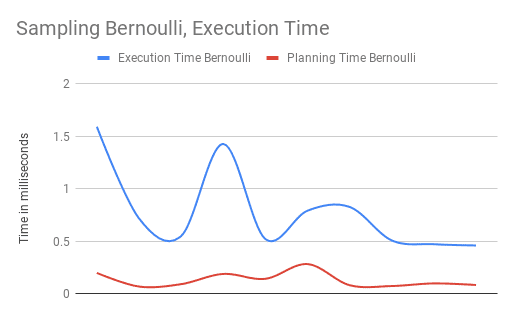
The average execution time in my case for the BERNOULLI was 0.7852ms
compared to the 261.367ms of the OFFSET and 188.8964ms of the ORDER
techniques.
Let’s do the same with SYSTEM
SELECT * FROM products
TABLESAMPLE SYSTEM(1) LIMIT 10;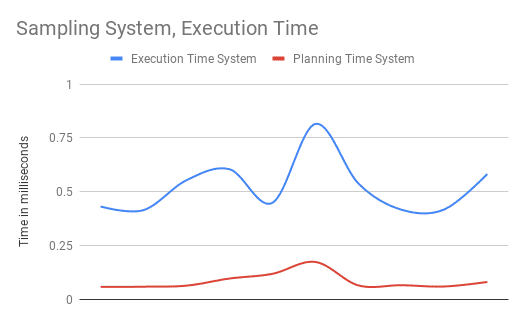
As we would expect, since SYSTEM works on page level it is faster,
but in my case it was not “significantly” faster, the average execution
time was 0.5228ms compared to the 0.7852ms of the BERNOULLI sampling.
One thing to notice though is that both BERNOULLI and SYSTEM do not
return the same amount of records each time they are executed, and you
should take that into consideration for your queries.
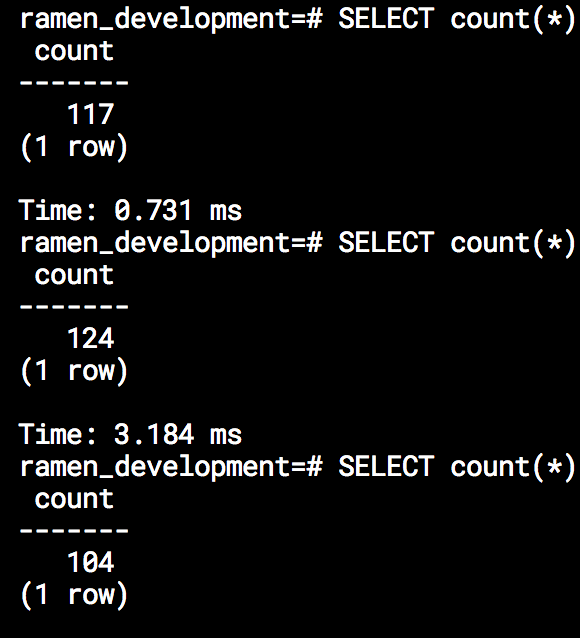
Specially SYSTEM can have large variations since it can hit pages with not
so many records.